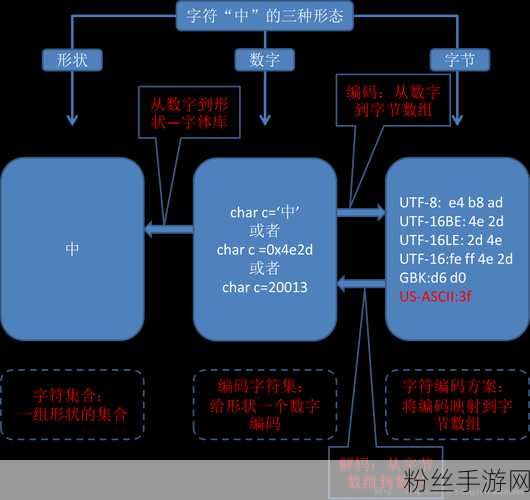
日文编码系统的基础
日本在信息技术的发展中,形成了独特的字符编码体系。最常见的有Shift-JIS、EUC-JP和UTF-8等。这些编码方式各自承担着不同的功能,以确保能够有效地表示汉字、平假名和片假名等多种字符。
Shift-JIS与乱码问题
Shift-JIS是早期为兼容ASCII而设计的一种双字节编码。在这种情况下,每个字符可以用一个或两个字节来表示。当文本中的某些部分使用不正确或不匹配的编码进行解码时,就会导致乱码现象。例如,从一个以UTF-8格式保存的数据文件转存到需要Shift-JIS格式的软件中,该软件可能无法正确识别原本应该显示的人物姓名或地点名称,而呈现出一些奇怪符号或者问号,这直接影响了用户体验。
EUC-JP的重要性及其局限性
EUC-JP是一种较新的日本语字符集,它对计算机处理能力要求相对较低,更适合旧版操作系统。然而,在现代互联网环境下,其支持度逐渐下降。有时候,将EUC-JP数据传输至只支持其他编译标准的平台,会造成文字失真。如果没有采取必要措施,比如提前确认所选目标平台是否能接受此类内容,将很容易遇到各种形式的乱码困扰,这不仅让人感到沮丧,也使得沟通变得极其困难。
UTF-8为何受到青睐
如今,UTF-8成为了全球范围内应用最广泛且灵活性最高的一种网页文本字体转换方案。它可同时向后兼容ASCII,并能覆盖所有Unicode标准中的语言,包括中文、阿拉伯文甚至是表情符号。因此,不同国家之间的信息交换更加顺畅。不过,当涉及到历史遗留的问题,如老旧程序依然采用的是其它更古老类型(例如EUC)时,很可能出现混乱,使得信息一旦被错误解析便难以恢复.

避免乱码的方法与技巧
为了减少因不同编码引起的不便,可以考虑几个简单方法。首先,对输入输出过程中的每一步都保持一致,例如,只选择一种统一使用并经过验证过的新型编辑器进行代码书写。同时,加设自动检测机制也十分重要,通过脚本监测当前使用何种协议,以及及时提示用户有关潜在风险,有助于建设良好的工作习惯。此外,对于关键项目而言,应当定期备份,以防万一出现不可逆转损坏的时候仍保留路数解决方案。
实战案例分析:如何修复乱码?
实例研究:A公司接收了一批来自海外合作方的数据包,其中包含大量客户订单信息,但由于双方所用编程语言存在差异,最终展现在数据库里的却是成串罕见称谓。“???”、“%$@!”之类无意义字符串填满整个页面,让事情陷入僵局。而B公司的运维团队通过确认源头文件所在的位置,以及明确重构规则,再结合合适工具进行了快速反查检索成功找回所有真正需恢复内容。从这例子里,我们可以看到跨国交流过程中尽量优化搭建资料库结构以及清楚界面交互设置都是阳光化管理必不可少环节之一!