在手游行业,数据的处理与分析是提升用户体验、优化游戏性能的关键,随着玩家数量的激增和游戏数据的海量增长,传统的数据处理方式已难以满足实时性和准确性的需求,为此,Spark和Flink两大分布式数据处理框架应运而生,它们各自以其独特的优势,在手游数据处理领域大放异彩。
Spark:手游数据的全能选手
Spark,作为大规模数据处理的统一分析引擎,以其分布式内存迭代计算框架著称,在手游领域,Spark凭借其高效的数据处理能力和丰富的生态系统,成为了众多游戏开发者的首选。
Spark的核心优势在于其基于内存的计算模式,这极大提升了数据处理的速度,对于手游来说,无论是用户行为分析、游戏日志处理,还是实时推荐系统的构建,Spark都能提供强有力的支持,Spark还支持多种编程语言,如Java、Scala、Python和R,这使得游戏开发者能够根据自己的技术栈,灵活选择最适合的开发语言。

在手游数据处理中,Spark的生态系统发挥了至关重要的作用,Spark SQL允许开发者使用SQL语句进行数据查询和分析,这对于熟悉关系型数据库的游戏数据分析师来说,无疑是一个巨大的福音,而Spark Streaming则专注于实时数据流的处理,能够实时捕捉和分析玩家的游戏行为,为游戏运营提供及时的数据支持,Spark还提供了机器学习库MLlib和图计算库GraphX,这些工具库为游戏开发者提供了丰富的算法和模型,帮助他们更好地理解和优化游戏数据。
Flink:手游数据的实时先锋
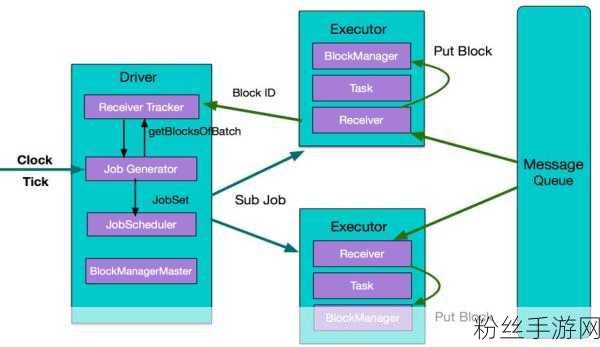
与Spark相比,Flink则是一个以流处理为核心的分布式数据处理框架,它不仅能够处理实时数据流,还能兼顾批处理任务,为手游行业提供了更为灵活和高效的数据处理方案。
Flink的高吞吐量和低延迟特性,使其在处理手游实时数据时表现出色,无论是玩家的实时登录信息、游戏内的交互数据,还是游戏外的社交媒体反馈,Flink都能在短时间内进行准确的分析和处理,这对于构建实时推荐系统、监控游戏性能和预防潜在的游戏故障具有重要意义。
Flink的另一个显著优势是其内置的状态管理和容错机制,在手游数据处理中,状态管理是一个至关重要的环节,Flink通过其高效的状态存储和检查点机制,确保了流处理任务的容错性和稳定性,即使在游戏高峰期,面对海量的数据涌入,Flink也能保持稳定的性能,为游戏开发者提供可靠的数据支持。
Spark与Flink:区别与应用场景
尽管Spark和Flink都是分布式数据处理框架的佼佼者,但它们在设计理念和应用场景上存在着显著的差异。
Spark以批处理为核心,同时支持流处理,它的内存计算模式使得在处理大规模数据集时具有极高的效率,Spark更适合于处理静态数据或需要大规模计算的任务,如游戏数据的离线分析、用户画像的构建等,而Flink则专注于流处理任务,其设计上实现了极低的延迟和出色的状态管理,这使得Flink在处理实时数据流时具有显著的优势,如实时推荐系统的构建、游戏性能的实时监控等。
在手游领域,Spark和Flink各自找到了自己的用武之地,对于需要处理海量历史数据、进行复杂的数据分析和挖掘的游戏开发者来说,Spark无疑是一个理想的选择,而对于追求实时性、需要快速响应玩家行为变化的游戏运营者来说,Flink则是一个不可或缺的利器。
手游官方数据与用户认可
据某知名手游公司透露,自引入Spark和Flink以来,其游戏数据的处理效率得到了显著提升,Spark在处理大规模游戏日志和用户行为数据时,展现出了极高的性能和稳定性,而Flink则在实时推荐系统和游戏性能监控方面发挥了重要作用,有效提升了玩家的游戏体验和游戏的整体运营效果。
用户认可数据方面,该手游公司在引入Spark和Flink后,其用户满意度和留存率均有了明显的提升,玩家对于游戏的实时反馈和个性化推荐表示高度赞赏,这也进一步验证了Spark和Flink在手游数据处理领域的卓越表现。
Spark和Flink作为分布式数据处理框架的佼佼者,在手游领域各自展现出了独特的优势和价值,它们不仅提升了游戏数据的处理效率和质量,还为游戏开发者提供了更为灵活和高效的数据处理方案,随着手游行业的不断发展,Spark和Flink将继续发挥重要作用,为游戏数据的处理和分析注入新的活力。